Rahul Sajnani

I am a Computer Science Ph.D. Candidate at Brown University advised by Srinath Sridhar. My current research interests revolves around understanding and manipulating implicit learnt representations of foundational models such as Stable Diffusion, Video Diffusion Models, CLIP, and DinoV2 to extend their capabilities for geometry editing, novel view synthesis, scene reconstruction, and motion control!
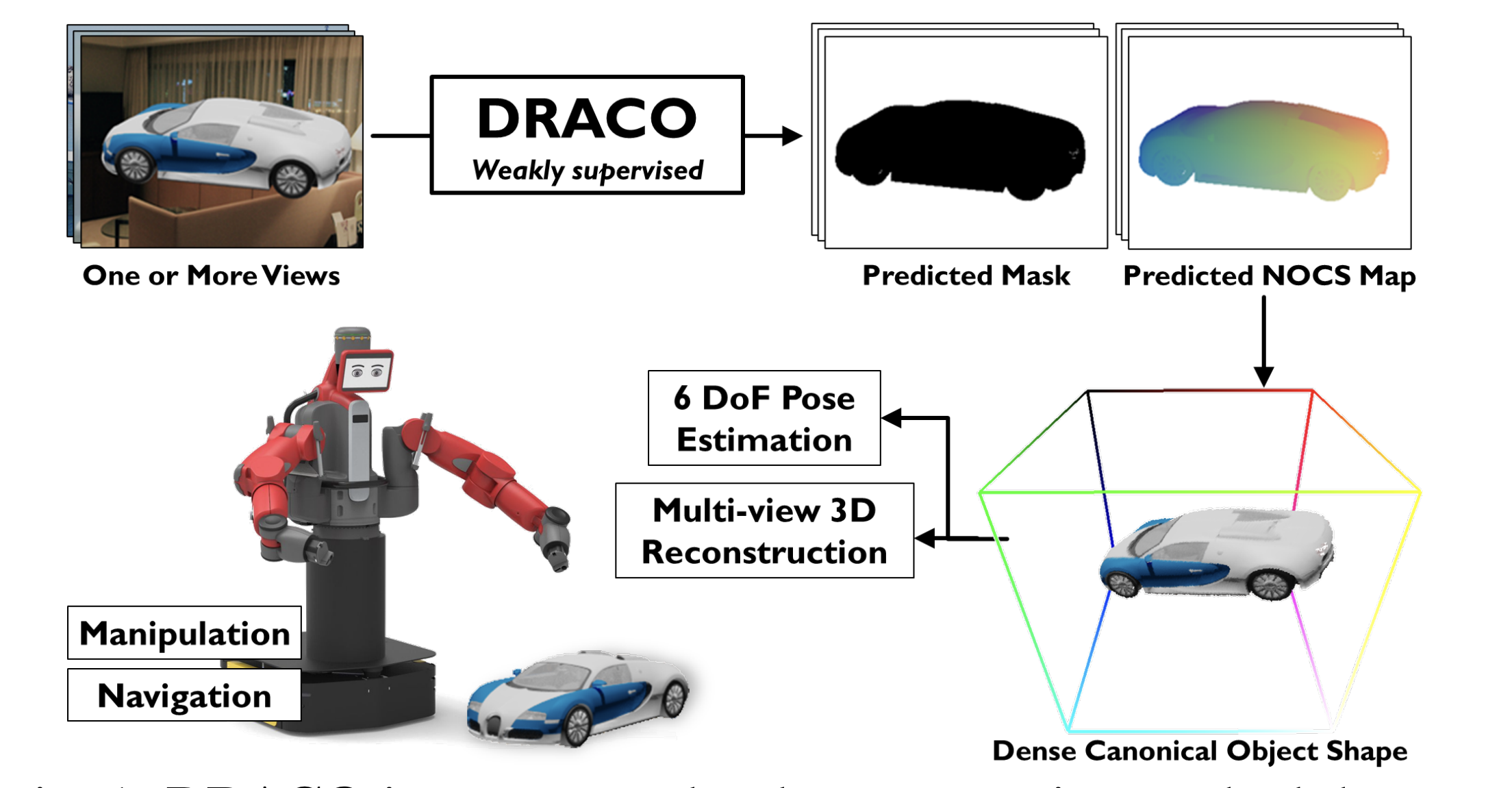
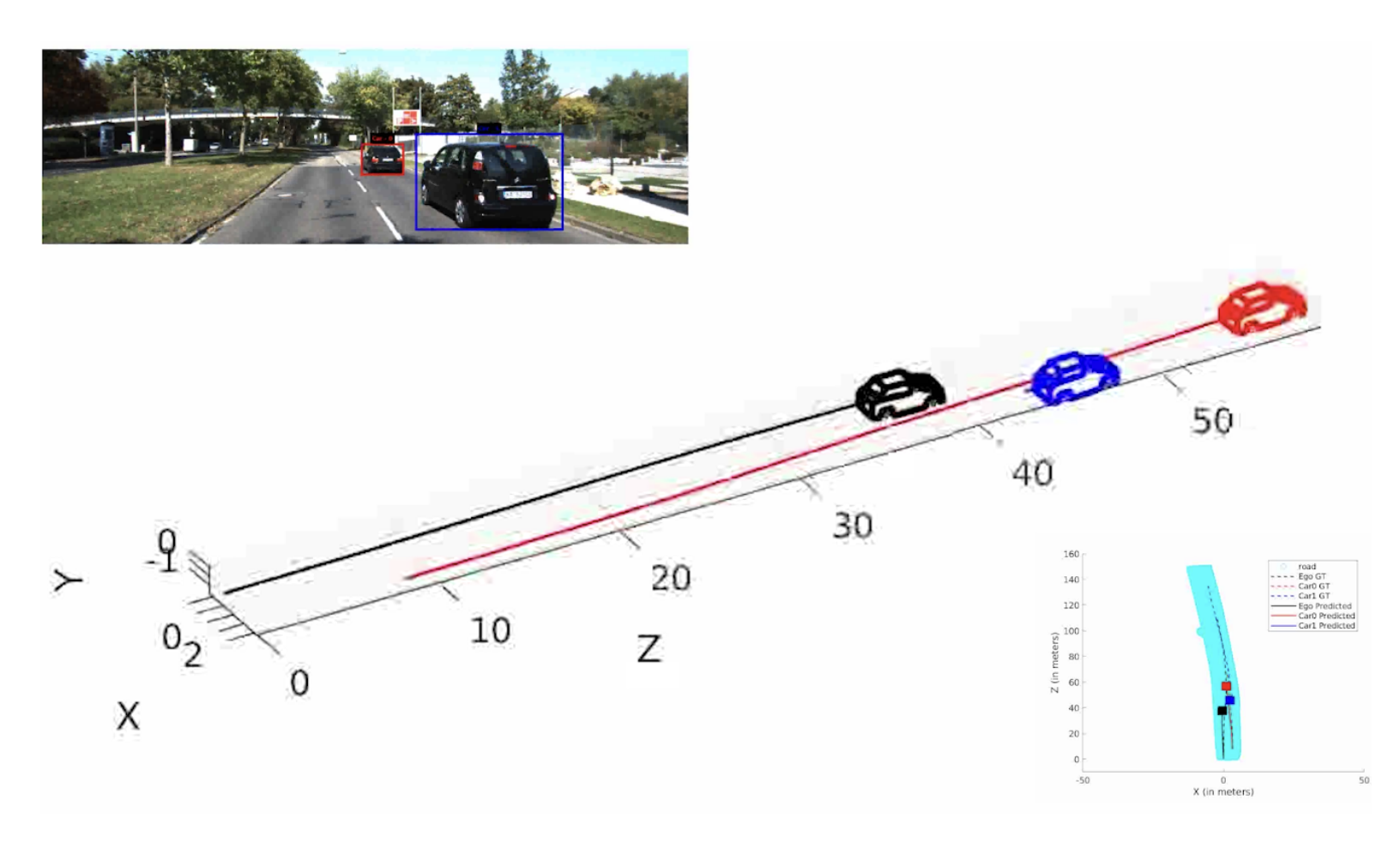
My research also delves into estimating canonical representations of objects [1,2,3] and modeling their inter-object interactions [4]. Prior to object understanding, I have also worked on visual localization of automobiles for SLAM [5] and managing the self-driving car of RRC, IIIT-Hyderabad.
I am fortunate to be advised by Srinath Sridhar, Leonidas Guibas, George Konidaris, Daniel Ritchie, Jeroen Vanbaar, Kapil Katyal, K. Madhava Krishna, Matheus Gadelha, and Kavita Vemuri.
Google Scholar / Email / GitHub / X / Linkedin / ResearchGate
Featured News
| May 12, 2025 | I received an Outstanding Reviewer award at CVPR 2025! |
|---|---|
| Apr 02, 2025 | Our work GeoDiffuser received the Best Student Paper at WACV 2025 |
| Oct 28, 2024 | Our work GeoDiffuser is accepted to WACV 2025 |
| Oct 24, 2024 | I will present literature on Video Diffusion Models with a focus on camera/motion conditioned models at Brown IVL & BVC. See slides here. |
| Apr 01, 2024 | I will present GeoDiffuser, a method to perform geometry-based image editing with T2I diffusion models at NYC Computer Vision Day. Our work does not need any training or model fine-tuning! |
| Jun 24, 2023 | I will join Amazon Robotics as an Applied Scientist to improve robot perception and item identification using Generative models. |
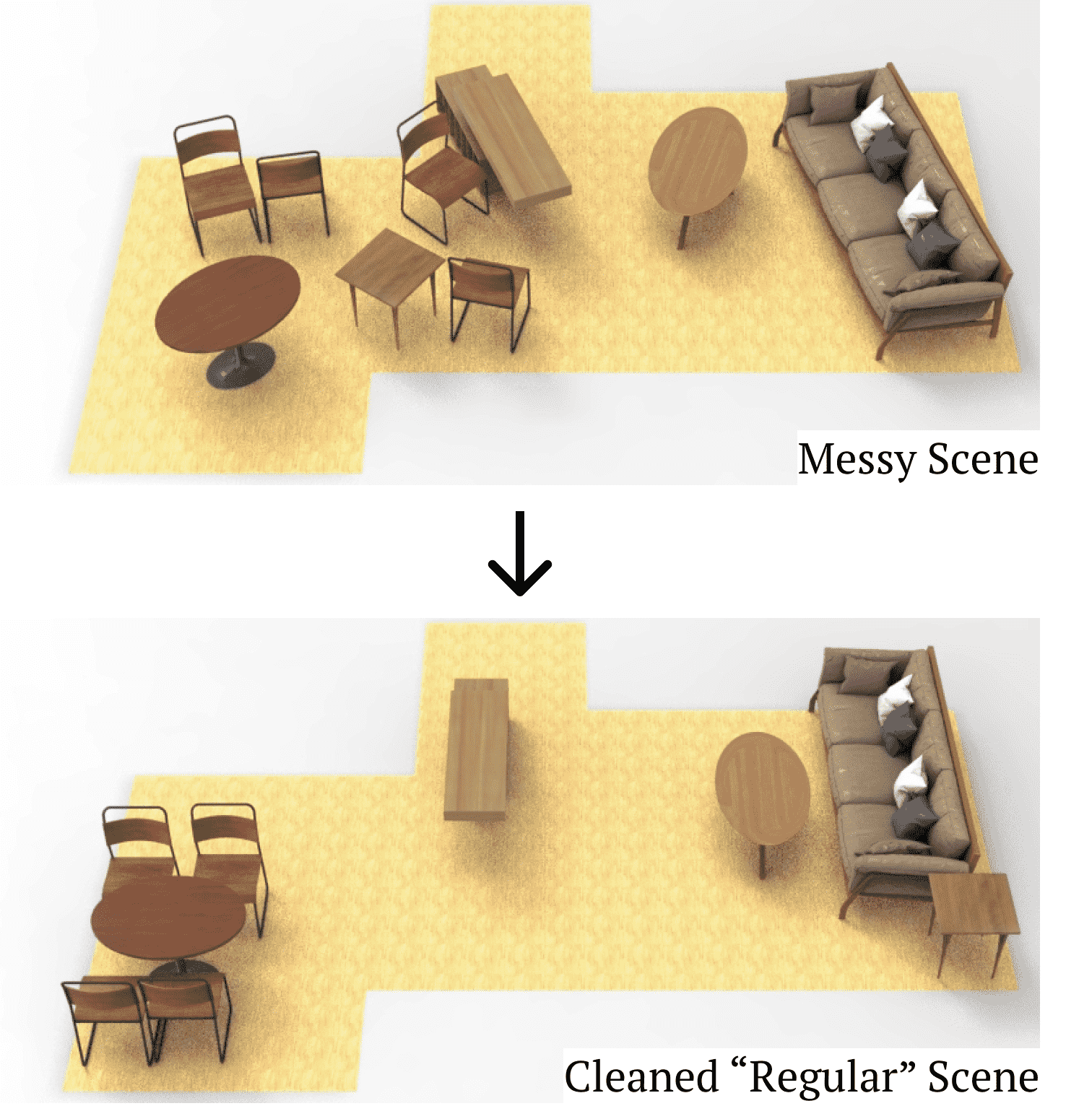
| Jun 20, 2023 | Check out our works Cafi-Net & Lego-Net at CVPR 2023! |
| Jun 01, 2022 | We will be presenting ConDor, a method to perform unsupervised 3D pose canonicalization of full and partial shapes at CVPR 2022. Our work also performs automatic co-part segmentation! |